

DeepSeek-R1-Zero обучена исключительно с использованием крупномасштабного обучения с подкреплением (RL), без предварительной стадии с использованием контролируемой донастройки (SFT). По словам DeepSeek, такой подход привел к естественному появлению «многочисленных мощных и интересных поведенческих паттернов рассуждения», включая самопроверку, рефлексию и генерацию обширных цепочек размышлений (CoT).
«Примечательно, что [DeepSeek-R1-Zero] является первым открытым исследованием, подтвердившим, что способности рассуждения в LLM могут быть стимулированы исключительно благодаря RL, без необходимости SFT», — объяснили исследователи DeepSeek. Этот рубеж не только подчеркивает инновационные основы модели, но и прокладывает путь для прогресса в ИИ, сосредоточенном на RL и рассуждениях.
Однако возможности DeepSeek-R1-Zero сопровождаются определенными ограничениями. Основные проблемы включают «бесконечные повторы, плохую читабельность и смешение языков», которые могут представлять значительные трудности в реальных приложениях. Для устранения этих недостатков DeepSeek разработала свою флагманскую модель: DeepSeek-R1.
Представляем DeepSeek-R1
DeepSeek-R1 развивает успехи своего предшественника, включая холодный старт данных до обучения с подкреплением. Этот дополнительный этап предобучения усиливает способности модели к рассуждению и решает многие ограничения, отмеченные в DeepSeek-R1-Zero.
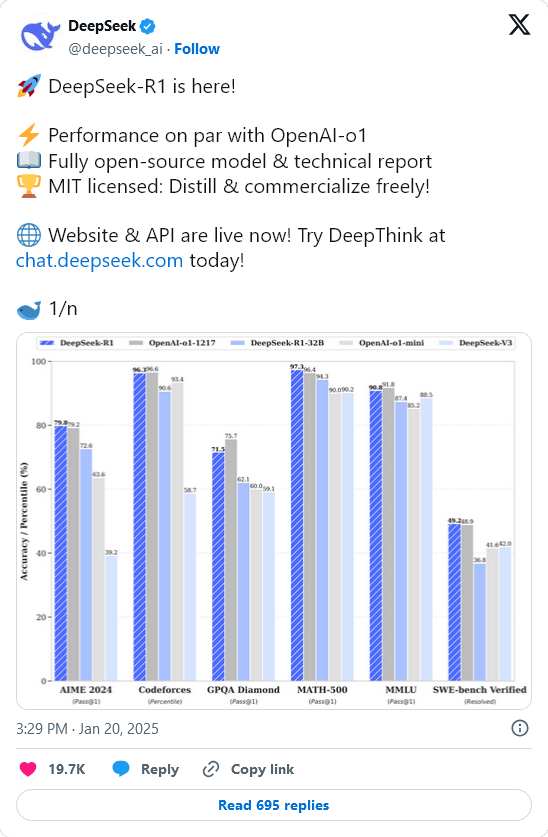
Примечательно, что DeepSeek-R1 достигает производительности, сопоставимой с широко известной системой o1 от OpenAI, в задачах по математике, программированию и общему рассуждению, укрепляя свое положение как ведущий конкурент.
DeepSeek приняла решение открыть доступ как к DeepSeek-R1-Zero, так и к DeepSeek-R1 вместе с шестью уменьшенными дистиллированными моделями. Среди них, DeepSeek-R1-Distill-Qwen-32B продемонстрировала выдающиеся результаты, даже обогнав o1-mini от OpenAI по нескольким критериям.
- MATH-500 (Pass@1): DeepSeek-R1 достигла 97.3%, превзойдя OpenAI (96.4%) и других ключевых конкурентов.
- LiveCodeBench (Pass@1-COT): дистиллированная версия DeepSeek-R1-Distill-Qwen-32B набрала 57.2%, что стало выдающимся результатом среди меньших моделей.
- AIME 2024 (Pass@1): DeepSeek-R1 достигла 79.8%, устанавливая впечатляющий стандарт в решении математических задач.
Путь, приносящий пользу всей отрасли
DeepSeek поделилась информацией о своей строгой системе разработки моделей, основанных на рассуждениях, которая сочетает комбинацию контролируемой донастройки и обучения с подкреплением.
По заявлению компании, процесс включает два этапа SFT для установления базовых игнорирующих и неигнорирующих способностей, а также два этапа RL, специально предназначенные для обнаружения продвинутых паттернов рассуждения и согласования этих возможностей с человеческими предпочтениями.
«Мы считаем, что наша методология принесет пользу отрасли, создавая более совершенные модели», — отметил DeepSeek, подразумевая потенциал их методологии для вдохновения будущего прогресса в области ИИ.
Одним из выдающихся достижений их подхода, ориентированного на RL, является способность DeepSeek-R1-Zero выполнять сложные паттерны рассуждения без предварительных инструкций от человека, что является первым в сообществе открытых исследований ИИ.
Важность дистилляции
Исследователи DeepSeek также подчеркнули важность дистилляции — процесса переноса способностей к рассуждению от более крупных моделей к меньшим и более эффективным, стратегию, которая позволила добиться прироста производительности даже для меньших конфигураций.
Меньшие дистиллированные версии DeepSeek-R1 — такие как версии 1.5B, 7B и 14B — смогли продемонстрировать конкурентоспособность в узкоспециализированных приложениях. Эти дистиллированные модели могут превзойти результаты, достигнутые в результате RL обучения для моделей сопоставимого размера.
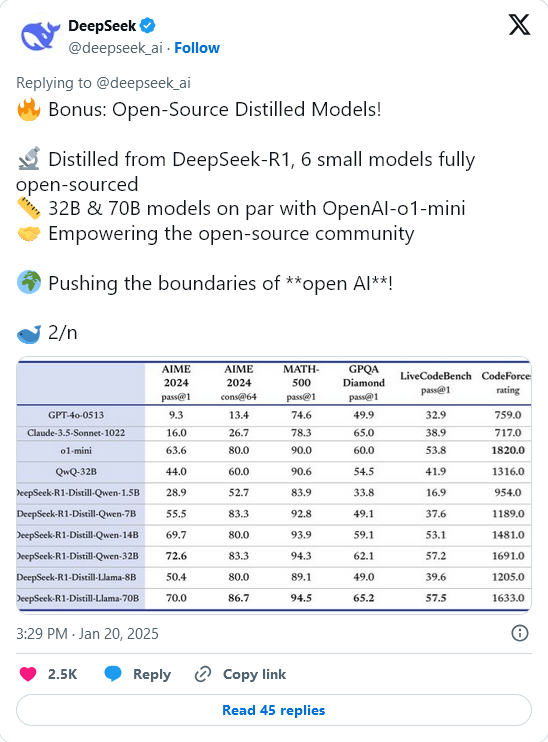
Для исследователей эти дистиллированные модели доступны в конфигурациях от 1.5 миллиарда до 70 миллиардов параметров, поддерживая архитектуры Qwen2.5 и Llama3. Такая гибкость позволяет использовать их в широком диапазоне задач, от программирования до понимания естественного языка.
DeepSeek приняла MIT лицензию для своего репозитория и весов, предоставляя разрешения на коммерческое использование и последующие модификации. Производные работы, такие как использование DeepSeek-R1 для обучения других крупных языковых моделей (LLM), разрешены. Однако пользователи конкретных дистиллированных моделей должны обеспечивать соблюдение лицензий оригинальных базовых моделей, таких как лицензии Apache 2.0 и Llama3.
Источник: Artificial Intelligence News
